Business continuity and disaster recovery are two terms that are frequently used interchangeably in UK boardrooms, IT departments, and insurance discussions. This conflation is understandable — both concepts deal with keeping your business operational when things go wrong — but it is also problematic, because the two disciplines serve fundamentally different purposes, address different risks, and require different planning approaches. An organisation that confuses them may find itself well-prepared for one type of disruption whilst completely exposed to another.
Understanding the distinction between business continuity and disaster recovery is not an academic exercise. It has real, practical implications for how you allocate your budget, structure your planning, assign responsibilities, and test your preparedness. A business that invests heavily in disaster recovery infrastructure but neglects business continuity planning may be able to restore its servers after a data centre fire but have no idea how to serve its customers during the weeks those servers are being rebuilt. Conversely, a business with excellent continuity plans but inadequate disaster recovery may know exactly how to operate without technology but lack the ability to restore its systems when the crisis is over.
This guide clarifies the distinction, explains how the two disciplines relate to each other, and provides practical guidance for UK businesses seeking to develop comprehensive resilience against disruption.
Defining Business Continuity
Business continuity is the overarching discipline concerned with ensuring that an organisation can continue to deliver its critical products and services during and after a disruptive event. It encompasses everything the organisation needs to keep operating — people, processes, technology, facilities, supply chains, and communications. Business continuity planning asks the question: "If something disrupts our normal operations, how do we continue to serve our customers and fulfil our obligations?"
The scope of business continuity is deliberately broad. It considers disruptions of every kind — not just technology failures, but also pandemics, extreme weather, supply chain interruptions, loss of key personnel, building evacuations, civil unrest, and regulatory actions. For each potential disruption, business continuity planning identifies the critical functions that must continue, determines acceptable levels of degradation, and develops strategies and procedures for maintaining those functions under adverse conditions.
A business continuity plan might include procedures for operating without your normal office building, processes for manual workarounds when technology systems are unavailable, communication protocols for keeping staff, customers, and stakeholders informed, arrangements with alternative suppliers if your primary supplier is affected, and succession planning for key personnel. The plan is fundamentally about the business — its operations, its people, and its obligations — rather than about any specific technology or infrastructure.
Key Components of a Business Continuity Programme
A comprehensive business continuity programme comprises several interconnected elements that work together to create genuine organisational resilience. Leadership and governance sit at the top — without clear board-level ownership and accountability, continuity planning remains a theoretical exercise confined to a document that nobody reads. The programme needs a designated owner, a steering committee with cross-functional representation, and regular reporting to the board on the organisation's state of readiness.
Business impact analysis forms the analytical foundation. This is the rigorous process of mapping every business function, understanding the dependencies between them, and quantifying the financial, operational, reputational, and regulatory impact of each function's disruption over time. The output is a prioritised list of critical functions with defined recovery timeframes — the data that drives every subsequent planning decision. Without a thorough business impact analysis, your continuity plan is built on assumptions rather than evidence.
Strategy development follows the analysis. For each critical function, you must identify one or more strategies for maintaining operations during disruption. Strategies might include remote working arrangements, mutual aid agreements with partner organisations, alternative premises, manual workarounds for automated processes, or diversified supply chains. The key is that each strategy must be practical, tested, and resourced — not merely documented.
Plan documentation captures the strategies, procedures, roles, and contact information needed to execute a coordinated response. Plans should be concise, action-oriented, and accessible — stored in multiple locations including off-site and offline copies that remain available even if your entire IT infrastructure is compromised. Finally, exercising and testing validates that your plans actually work, and a continuous improvement cycle ensures that lessons from tests and real incidents are incorporated into updated plans.
ISO 22301 is the international standard for business continuity management systems. It provides a framework for planning, establishing, implementing, operating, monitoring, reviewing, maintaining, and continuously improving a documented management system to protect against, reduce the likelihood of, and ensure recovery from disruptive incidents. While certification is not mandatory for most UK businesses, aligning your business continuity programme with ISO 22301 demonstrates a rigorous, systematic approach that satisfies regulators, clients, and insurers. Many UK government contracts now require evidence of business continuity capability aligned with this standard.
Defining Disaster Recovery
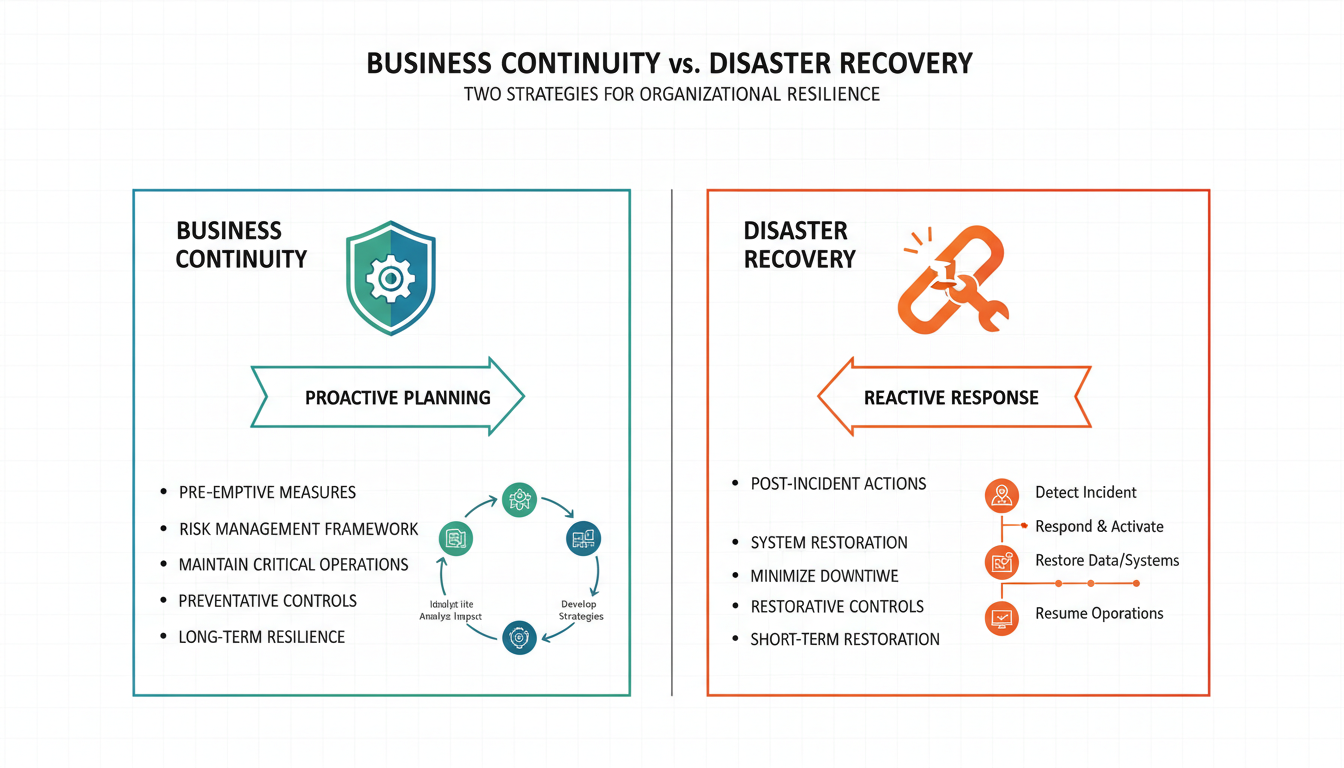
Disaster recovery is a subset of business continuity that focuses specifically on the restoration of technology systems and data following a disruptive event. While business continuity asks "how do we keep operating?", disaster recovery asks "how do we restore our technology?" The two questions are related but distinct — you need answers to both.
A disaster recovery plan addresses the technical specifics of restoring your IT infrastructure: which systems need to be recovered first, what recovery time objectives apply to each system, what recovery point objectives define acceptable data loss, where recovery will take place, what technology and resources are required, and who is responsible for each recovery task. It is a detailed, technical document that provides step-by-step procedures for restoring servers, databases, applications, networks, and communications systems.
Disaster recovery planning revolves around two critical metrics that every UK business should define for each of its systems. The Recovery Time Objective (RTO) specifies the maximum acceptable duration of a system outage — how quickly must the system be restored? The Recovery Point Objective (RPO) specifies the maximum acceptable amount of data loss measured in time — how much data can you afford to lose? These metrics drive every technical decision in your disaster recovery plan, from your backup frequency and retention policies to your choice of recovery infrastructure.
Understanding RTO and RPO in Practical Terms
Recovery Time Objective and Recovery Point Objective sound like abstract metrics, but they translate directly into business decisions that every director should understand. Consider a retail business that processes online orders. If its e-commerce platform goes down, an RTO of four hours means the business accepts being unable to take orders for up to four hours. An RPO of one hour means the business accepts losing up to one hour's worth of order data — any orders placed in the hour before the disaster may need to be re-entered or reconciled manually.
These metrics must be defined through consultation with the business, not by the IT department alone. The IT team can advise on what is technically achievable and at what cost, but only the business can determine what level of disruption is commercially acceptable. A four-hour RTO might be perfectly acceptable for an internal reporting system but catastrophic for a customer-facing payment platform. An RPO of twenty-four hours might be tolerable for archived documents but entirely unacceptable for a real-time financial trading system.
The relationship between RTO, RPO, and cost is approximately exponential. Reducing your RTO from twenty-four hours to four hours might double your disaster recovery costs. Reducing it further from four hours to fifteen minutes might increase costs tenfold. The same principle applies to RPO — achieving near-zero data loss requires real-time replication technology that costs significantly more than daily backups. Defining appropriate RTOs and RPOs for each system allows you to invest proportionally, spending the most on protecting the systems that matter most to your business operations.
Business Continuity
- Covers the entire organisation and all functions
- Addresses people, processes, technology, and facilities
- Focuses on maintaining operations during disruption
- Considers all types of disruptive events
- Owned by senior management or the board
- Includes communication, supply chain, and HR
- Answers: "How do we keep the business running?"
Disaster Recovery
- Focuses specifically on IT systems and data
- Addresses servers, networks, applications, databases
- Focuses on restoring technology after an incident
- Considers events that affect IT infrastructure
- Owned by the IT department or IT service provider
- Includes backup, replication, and failover systems
- Answers: "How do we restore our technology?"
How Business Continuity and Disaster Recovery Work Together
Business continuity and disaster recovery are not alternatives — they are complementary disciplines that together provide comprehensive organisational resilience. Think of business continuity as the strategic umbrella and disaster recovery as one of several tactical components beneath it.
When a major disruption occurs — say, a fire destroys your office — your business continuity plan activates immediately. It directs staff to alternative working locations, implements manual workarounds for critical processes, manages communications with customers and suppliers, and coordinates the overall response. Simultaneously, your disaster recovery plan activates within the IT domain, restoring servers from backup, failing over to secondary systems, and working to bring your technology estate back to full operation.
Neither plan is sufficient alone. Without business continuity, you might restore your servers perfectly but have no way to operate because your staff have nowhere to work and your customers have not been informed. Without disaster recovery, you might keep your business running through manual processes for a day or two, but without the ability to restore your technology, those manual processes eventually become unsustainable.
Real-World Scenarios: When the Plans Are Tested
Consider a professional services firm in Manchester whose office building suffered severe flooding during Storm Christoph in January 2021. Their business continuity plan activated immediately: staff received automated notifications directing them to work from home, client communications were sent within two hours, and critical deadlines were redistributed among teams in unaffected offices. Simultaneously, their disaster recovery plan kicked in — servers hosted in a data centre were unaffected, but the on-premise phone system and local NAS storage were damaged. Cloud-based backup allowed data restoration to proceed whilst the business continued operating remotely.
Without business continuity planning, the firm would have restored its servers but had no coordinated way to redirect work, communicate with clients, or maintain service levels during the disruption. Without disaster recovery, the remote working arrangements would have been undermined by the inability to access critical data and applications. The two plans worked in concert, each covering aspects that the other did not address.
Another instructive example involves a logistics company targeted by a ransomware attack. Business continuity procedures enabled the warehouse to continue processing orders using paper-based picking lists and manual dispatch coordination — processes that had been documented and practised precisely for this scenario. The disaster recovery plan provided the roadmap for restoring encrypted systems from immutable cloud backups, a process that took seventy-two hours to complete fully. During those three days, the business continued to operate at approximately sixty per cent capacity rather than shutting down entirely.
Building a Business Continuity Plan for UK Businesses
A practical business continuity plan for a UK business does not need to be hundreds of pages long, but it does need to cover certain essential elements systematically.
Business Impact Analysis
The foundation of any business continuity plan is a business impact analysis (BIA). This exercise identifies every business function, assesses the impact of its disruption over time, determines the maximum acceptable outage duration, and identifies the resources (people, technology, facilities, information) required to maintain or restore each function. The BIA provides the data that drives all subsequent planning decisions — without it, you are guessing about priorities and tolerances.
Risk Assessment
Identify the specific threats that could disrupt your operations. For UK businesses, common threats include cyber attacks (particularly ransomware), extreme weather events (flooding is a growing risk across the UK), utility failures (power outages, internet disruption), pandemic illness, supply chain failures, and building-specific incidents (fire, structural damage, contamination). Assess each threat for likelihood and impact, and prioritise your planning efforts accordingly.
| Threat | Likelihood | Impact | Priority |
|---|---|---|---|
| Ransomware attack | High | Critical | 1 |
| Internet outage | Medium | High | 2 |
| Flooding | Medium | High | 3 |
| Power failure | Medium | Medium | 4 |
| Pandemic illness | Low-Medium | High | 5 |
| Building fire | Low | Critical | 6 |
Recovery Strategies and Workarounds
For each critical function identified in your business impact analysis, you need at least one recovery strategy — and ideally more than one, in case your primary strategy is itself affected by the disruption. Recovery strategies fall into several broad categories, and most businesses will employ a combination across their different functions.
Diversification strategies reduce single points of failure before a disruption occurs. Examples include maintaining multiple internet connections from different providers, cross-training staff so that no single person is indispensable to a critical process, and maintaining relationships with alternative suppliers who can step in if your primary supplier is affected. These strategies reduce the likelihood that any single event will disrupt a critical function.
Replication strategies maintain standby capability that can be activated when the primary resource fails. This includes secondary office space that can be activated at short notice, mirrored IT systems in a separate data centre, and backup communication channels such as mobile phones and satellite internet. Replication is more expensive than diversification but provides faster recovery for the most critical functions.
Manual workaround strategies define how critical processes can continue without their normal technology support. Every technology-dependent process should have a documented manual fallback, even if it is slower and less efficient. The goal is not to maintain normal productivity but to maintain minimum viable operations until technology is restored. These workarounds must be practised regularly — staff who have never performed a process manually will struggle to do so under the pressure of a real disruption.
Communication and Crisis Management
Effective communication during a disruption is often the difference between an orderly response and organisational chaos. Your business continuity plan must include a crisis communication framework that covers internal communication (keeping staff informed and coordinated), external communication (notifying customers, suppliers, and partners), regulatory communication (reporting to regulators where required, such as ICO notification for data breaches within seventy-two hours), and media communication (managing public perception if the incident attracts press attention).
Establish a clear chain of command for crisis decision-making. Identify who has the authority to activate the business continuity plan, who leads the response for different types of incidents, and who serves as the primary spokesperson. Document contact details for all key personnel in multiple formats — printed wallet cards, a secure cloud-based contact list, and an automated notification system that can reach everyone simultaneously. During a major disruption, your normal communication channels (office phones, email, intranet) may be unavailable, so your crisis communication plan must use alternative channels that remain operational.
Building a Disaster Recovery Plan
Your disaster recovery plan should document the specific procedures for restoring every critical IT system, based on the RTOs and RPOs defined during your business impact analysis.
Backup Strategy
Your backup strategy is the foundation of disaster recovery. For UK businesses, we recommend following the 3-2-1 rule as a minimum: maintain at least three copies of your data, on at least two different types of media, with at least one copy stored off-site. For businesses with more stringent requirements, extend this to 3-2-1-1-0: three copies, two media types, one off-site, one offline (air-gapped), and zero errors (verified through regular test restores).
Cloud backup services — particularly those using UK-based data centres — provide an excellent foundation for disaster recovery. They offer geographic separation from your primary site, scalable storage capacity, encryption in transit and at rest, and automated backup scheduling. However, you must verify that your cloud backup provider stores data in the United Kingdom (or at minimum within the EEA) to maintain GDPR compliance, and you must test restoration regularly to ensure that your backups are actually recoverable when needed.
Recovery Infrastructure Options
Your disaster recovery infrastructure — the systems and services that enable recovery — must be selected based on your defined RTOs and RPOs. For UK businesses, the primary options include cold standby (a pre-configured but powered-off recovery environment that can be activated within hours to days), warm standby (a partially active environment that receives periodic data updates and can be brought fully online within hours), and hot standby (a fully active, continuously replicated environment that can take over within minutes).
Cold standby is the least expensive option and is suitable for systems with RTOs measured in days. Warm standby suits systems with RTOs of several hours and is the most common choice for typical business applications. Hot standby provides near-instant failover but at a premium cost, and is typically reserved for mission-critical systems where even brief outages have severe consequences — payment processing platforms, emergency services systems, or trading infrastructure.
Cloud-based disaster recovery services have made warm and hot standby significantly more affordable for UK SMEs. Services such as Azure Site Recovery, AWS Disaster Recovery, and specialist UK providers allow businesses to maintain replicated environments in the cloud without the capital expenditure of a dedicated secondary data centre. You pay for the standby resources on a monthly basis, and the cloud provider handles the underlying infrastructure, patching, and availability. This model transforms disaster recovery from a capital expense to an operational expense and makes enterprise-grade recovery capability accessible to businesses of all sizes.
Documentation and Recovery Runbooks
Your disaster recovery plan must include detailed, step-by-step runbooks for restoring each critical system. A runbook is not a high-level overview — it is a precise procedural document that an engineer can follow under pressure to restore a specific system, even if that engineer was not involved in the original setup. Each runbook should specify the system name and purpose, the RTO and RPO targets, prerequisites and dependencies, the exact recovery procedure with numbered steps, verification steps to confirm successful recovery, and contact details for escalation if issues arise.
Runbooks should be stored in at least three locations: within your main documentation system, in a printed binder kept in a secure off-site location, and in a cloud-based document store that is independent of your primary IT infrastructure. If a disaster takes down your entire IT environment, you need to be able to access your recovery procedures through alternative means. A recovery plan that is stored only on the servers it is supposed to help you recover is of no use whatsoever.
Testing: The Most Neglected Step
A business continuity plan that has never been tested is not a plan — it is a wish list. Testing is the single most important step in the entire planning process, yet it is also the most frequently neglected. A 2024 survey by the Business Continuity Institute found that 42% of UK organisations had never conducted a full test of their continuity plans, and a further 28% had not tested within the past two years.
Testing should be conducted at multiple levels. Desktop exercises walk through scenarios on paper, testing the logic and completeness of your plans without disrupting operations. Simulation exercises create realistic scenarios where team members must respond as they would during a real incident, testing communication, decision-making, and coordination. Full technical tests verify that your disaster recovery infrastructure works as designed — can you actually restore from backup within your RTO? Does your failover infrastructure actually work? Are your recovery procedures accurate and complete?
Every test will reveal gaps and weaknesses in your plans. This is not failure — it is the entire purpose of testing. Document every issue discovered, update your plans accordingly, and retest. The organisations that survive real disasters are those that found and fixed their weaknesses through testing rather than discovering them during an actual emergency.
Establishing a Testing Schedule
Testing should follow a structured annual calendar that escalates in complexity and realism. Quarterly desktop exercises provide frequent, low-disruption opportunities to review and refine your plans. These exercises involve gathering key personnel around a table, presenting a hypothetical scenario, and walking through the response step by step. They are inexpensive, require minimal time, and consistently reveal gaps in documentation, unclear responsibilities, and outdated contact information.
Twice-yearly simulation exercises test your team's ability to respond to specific scenarios under realistic conditions — these should involve actual decision-making, real communications, and time pressure. Unlike desktop exercises, simulations require participants to perform their roles as they would during a real incident, using actual communication channels and accessing real documentation. The difference between a desktop exercise and a simulation is the difference between reading about swimming and jumping into the pool.
Annual full technical tests verify that your disaster recovery infrastructure actually functions as designed — can you actually restore from backup within your RTO? Does your failover infrastructure work? Are your recovery procedures accurate and complete? These tests are the most disruptive and expensive, but they are also the most revealing. Organisations that conduct annual technical tests consistently achieve faster recovery times during real incidents than those that rely solely on desktop exercises.
Each test should have clearly defined objectives, success criteria, and a formal debrief process. Assign an independent observer to document the test — noting what went well, what went wrong, what was confusing, and what was missing from the plan. The debrief should produce a specific, time-bound action list for plan improvements, and those improvements should be verified in the next test cycle. Over time, this iterative process transforms your plans from theoretical documents into battle-tested operational procedures that your team can execute with confidence under real pressure.
Protect Your Business with Proper Continuity and Recovery Planning
Cloudswitched helps UK businesses develop, implement, and test comprehensive business continuity and disaster recovery plans. From business impact analysis and risk assessment through to backup infrastructure deployment and regular testing, we ensure your organisation is resilient against disruption. Our plans are practical, tested, and aligned with ISO 22301 and Cyber Essentials standards. Get in touch to discuss your continuity and recovery requirements.
Explore Cloud Backup Solutions
CloudSwitched
London-based managed IT services provider offering support, cloud solutions and cybersecurity for SMEs.









